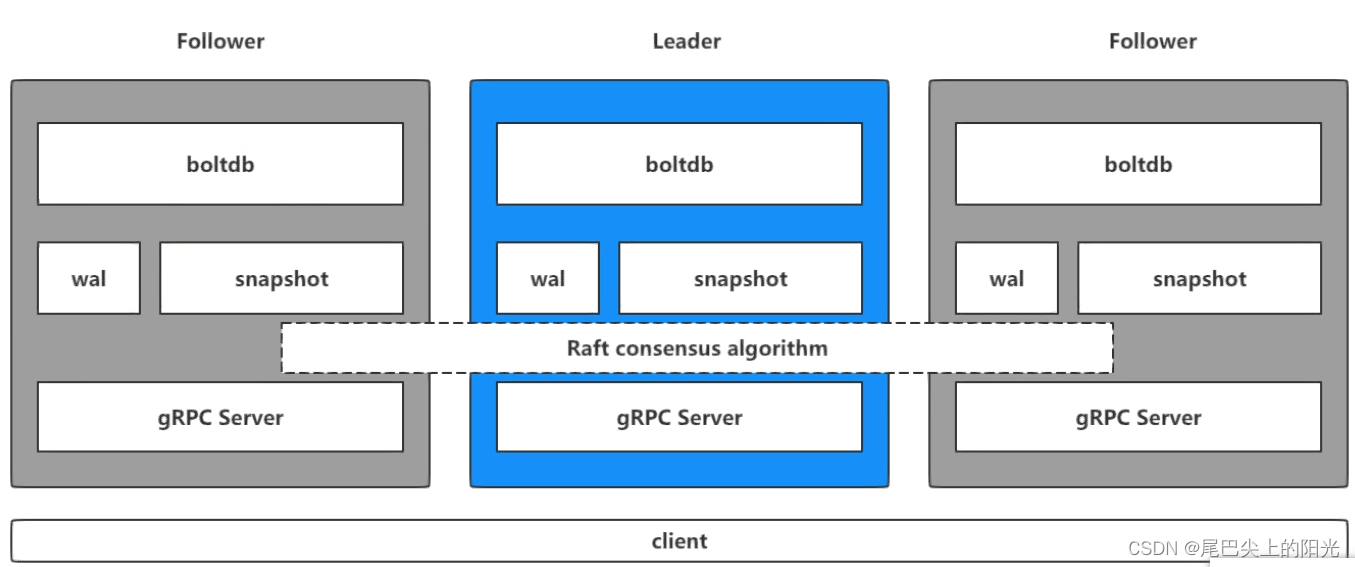
虽然将数据划分为训练集、验证集、测试集的方法是可行的,也相对常用,但这种方法对数据的划分相当敏感,为了得到对泛化性能的更好估计,我们可以使用交叉验证来评估每种参数组合的性能,而不是仅将数据单次划分为训练集与验证集。代码表示如下:
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import numpy as np
iris=load_iris()
X_trainval,X_test,y_trainval,y_test=train_test_split(iris.data,iris.target,random_state=0)
X_train,X_valid,y_train,y_valid=train_test_split(X_trainval,y_trainval,random_state=1)
print('训练集大小:{} 开发集大小:{} 测试集大小:{}'.format(X_train.shape[0],X_valid.shape[0],X_test.shape[0]))
best_score=0
for gamma in [0.001,0.01,0.1,1,10,100]:
for C in [0.001,0.01,0.1,1,10,100]:
#对每种参数组合都训练一个SVC
svm=SVC(gamma=gamma,C=C)
#交叉验证
scores=cross_val_score(svm,X_trainval,y_trainval,cv=5)
score=np.mean(scores)
if score>best_score:
best_score=score
best_parameters={'C':C,'gamma':gamma}
svm=SVC(**best_parameters)
svm.fit(X_trainval,y_trainval)要想使用5折交叉验证对C和gamma特定取值的SVM的精度进行评估,需要训练36*5=180个模型,可以想象,使用交叉验证的主要缺点就是训练所有的这些模型所需花费的时间。
下面的可视化说明了上述代码如何选择最佳参数设置:
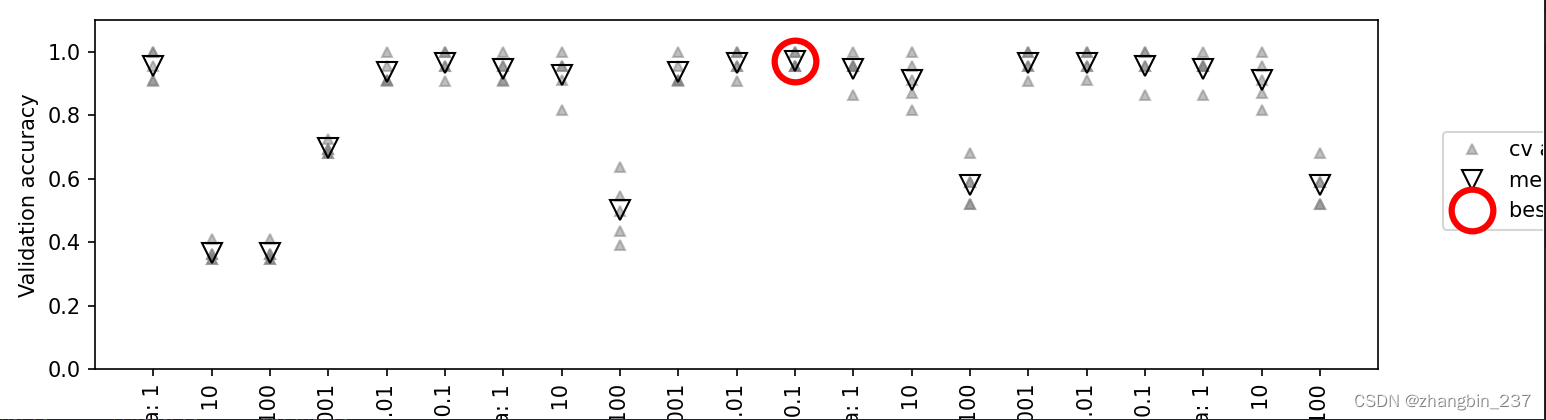
对于每种参数设置,需要计算5个精度值,交叉验证的每次划分都要计算一个精度值,然后,对每种参数设置计算平均验证精度,最后,选择平均验证精度最高的参数,用圆圈标记。
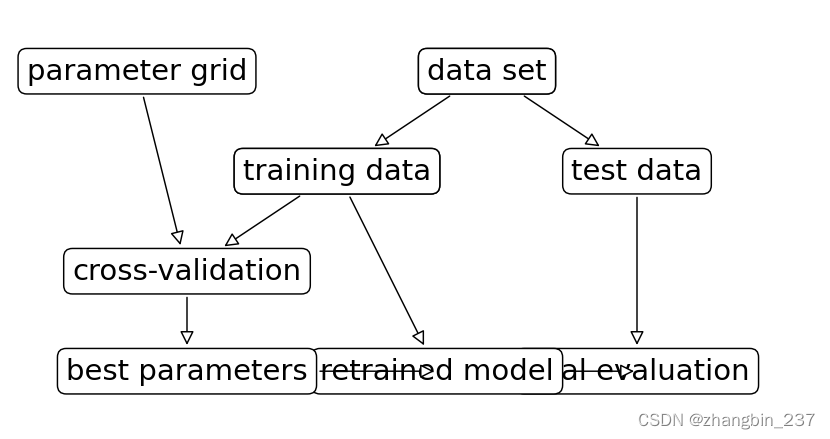
划分数据,运行网格搜索并评估最终参数的过程:
由于带交叉验证的网格搜索是一种常用的调参方法,因此scikit-learn提供了GridSearchCV类,它以估计器的形式实现了这种方法。要使用GridSearchCV类,我们首先要用一个字典指定要搜索的参数。然后GridSearchCV会执行所有必要的模型拟合。字典的键是我们想要尝试的参数设置。如果C和gamma想要的取值是0.001、0.01、0.1、1、10、100,可以将其转化为下面这个字典:
param_grid={'C':[0.001,0.01,0.1,1,10,100]
,'gamma':[0.001,0.01,0.1,1,10,100]}
print('Parameter grid:\n{}'.format(param_grid))
现在我们可以使用模型(SVC)、要搜索的参数网格(param_grid)与要使用的交叉验证策略将GridSearchCV类实例化:
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
grid_search=GridSearchCV(SVC(),param_grid,cv=5)GridSearchCV将使用交叉验证来代替之前用过的划分训练集和验证集方法。但是,我们仍需要将数据还分为训练集和测试集,以避免过拟合:
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=0)我们创建的grid_search对象的行为就像是一个分类器,我们可以对它调用标准的fit、predict、score方法。但我们在调用fit时,它会对param_grid指定的每种参数组合都进行交叉验证:
grid_search.fit(X_train,y_train)拟合GridSearchCV对象不仅会搜索最佳参数,还会利用得到最佳交叉验证性能的参数在整个训练集上自动拟合一个新模型。因此,fit完成的工作相当于本篇第一段代码的效果。GridSearchCV类提供了一个非常方便的接口,可以用predict和score方法来访问重新训练过的模型。
为了评估找到的最佳参数的泛化能力,我们可以在测试集上调用score:
score=grid_search.score(X_test,y_test)
print('测试集score:{:.2f}'.format(score))
利用交叉验证选择参数,我们实际上找到了一个在测试集上精度为97%的模型。重要的是,我们没有使用测试集来选择参数。我们找到的参数保存在best_params_属性中,而交叉验证最佳精度(对于这种参数设置,不同划分的平均精度)保存在best_score_中:
print('最佳参数:{}'.format(grid_search.best_params_))
print('最佳精度:{}'.format(grid_search.best_score_))
能够访问实际找到的模型,这有时是很有帮助的,比如查看系数或特征重要性。可以用best_estimator_属性来访问最佳参数对应的模型,它是在整个训练集上训练得到的:
print('最佳参数对应的模型:{}'.format(grid_search.best_estimator_))
由于grid_search本身具有predict和score方法,所以不需要使用best_estimator_来进行预测或评估模型。
1、分析交叉验证的结果
将交叉验证的结果可视化通常有助于理解模型泛化能力对所搜索参数的依赖关系。由于运行网格搜索的计算成本相当高,所以通常最高从相对比较稀疏且较小的网格开始搜索。然后我们可以检查交叉验证网格搜索的结果,可能也会扩展搜索范围。网格搜索的结果可以在cv_results_属性中找到,它是一个字典,其中保存了搜索的所有内容。你可以在下面的输出中看到,它包含许多细节,最好将其转换成pandas数据框后再查看:
results=pd.DataFrame(grid_search.cv_results_)
display(results.head())
results中每一行对应一种特定的参数设置。对于每种参数设置,交叉验证所有划分的结果都被记录下来,所有划分的平均值和标准差也被记录下来。由于我们搜索的是一个二维参数网格,所以最适合用热图可视化。我们首先提取平均验证分数,然后改变分数数组的形状,使其坐标轴分别对应C和gamma:
scores=np.array(results.mean_test_score).reshape(6,6)
mglearn.tools.heatmap(scores,xlabel='gamma',xticklabels=param_grid['gamma'],ylabel='C',yticklabels=param_grid['C'],cmap='viridis')
plt.show()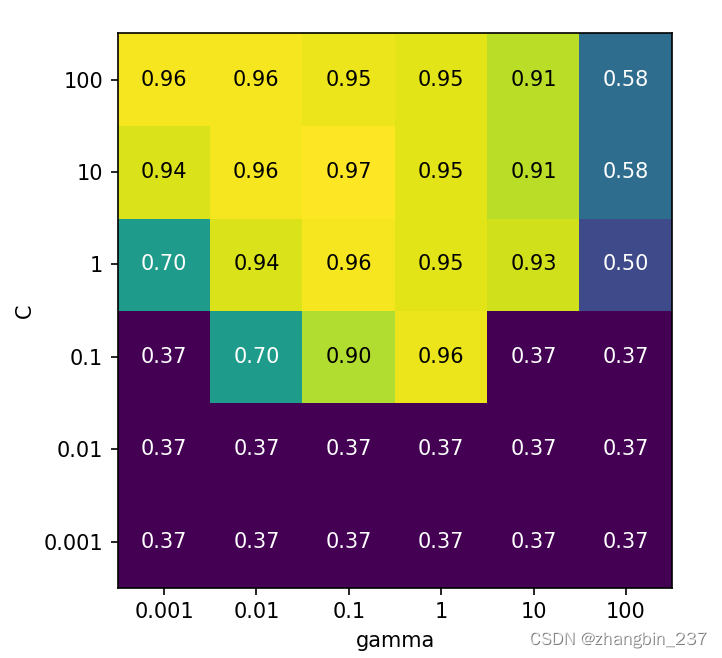
热图中的每个点对应于运行一次交叉验证以及一种特定的参数设置。颜色表示交叉验证的精度:浅色表示高精度,深色表示低精度。可以看到,SVC对参数设置非常敏感。对于许多种参数设置,精度都在40%左右,这是非常糟糕的:对于其他参数设置,精度约为96%。
我们可以从图中看出:
1、我们调节的参数对于获得良好的性能非常重要;这两个参数(C和gamma)都很重要,因为调节它们可以将精度从40%提高到96%
2、在我们选择的参数范围中也可以看到输出发生了显著的变化。
同样重要的是要注意,参数的范围要足够大,每个参数的最佳取值不能位于图像的边界上。
下面的例子,结果就不那么理想,因为选择的搜索范围不合适:
import mglearn.plots
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
iris=load_iris()
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=0)
fig,axes=plt.subplots(1,3,figsize=(13,5))
param_grid_linear={'C':np.linspace(1,2,6),'gamma':np.linspace(1,2,6)}
param_grid_one_log={'C':np.linspace(1,2,6),'gamma':np.logspace(-3,2,6)}
param_grid_range={'C':np.logspace(-3,2,6),'gamma':np.logspace(-7,-2,6)}
for param_grid,ax in zip([param_grid_linear,param_grid_one_log,param_grid_range],axes):
grid_search=GridSearchCV(SVC(),param_grid,cv=5)
grid_search.fit(X_train,y_train)
scores=grid_search.cv_results_['mean_test_score'].reshape(6,6)
scores_image=mglearn.tools.heatmap(scores,xlabel='gamma',xticklabels=param_grid['gamma'],ylabel='C',yticklabels=param_grid['C'],cmap='viridis',ax=ax)
plt.colorbar(scores_image,ax=axes.tolist())
plt.show()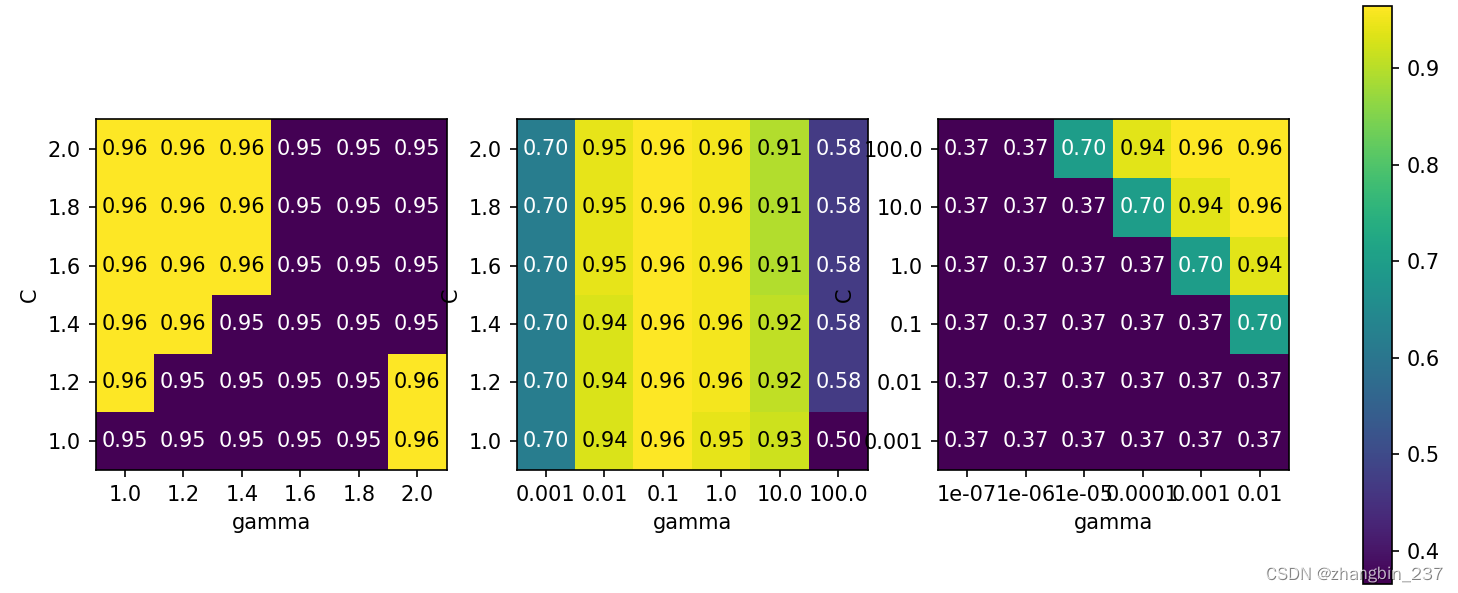
第一张图没有显示任何变化,整个参数网格的颜色相同,在这种情况下,这是由参数C和gamma不正确的缩放以及不正确的范围造成的。但如果对于不同的参数设置都看不到精度的变化,也可能是因为这个参数根本不重要。通常最好是开始时尝试非常极端的值,以观察改变参数是否会导致精度发生变化。
第二张图显示的是垂直条形模式。这表示只有gamma的设置对精度有影响。这可能意味着gamma参数搜索的范围是我们所关心的,而C参数并不是,也可能意味着C参数并不重要。
第三张图中C和gamma对应的精度都有变化。但可以看到,在图像的整个左下角都没有发生什么有趣的事情。我们在后面的网格搜索中可以不考虑非常小的值。最佳参数设置出现在右上角。由于最佳参数位于图像的边界,所以我们可以认为,在这个边界之外可能还有更好的取值,我们肯呢个希望改变搜索范围以包含这一区域内的更多参数。
基于交叉验证分数来调节参数网格是非常好的,也是搜索不同参数的重要性的好方法。但是,我们不应该在最终测试集上测试不同的参数范围,只有确切知道了想要使用的模型,才能对测试集进行评估。
2、在非网格的空间中搜索
在某些情况下,尝试所有参数的可能组合(正如GridSearchCV所做的那样)并不是一个好主意。例如SVC有一个kernel参数,根据所选的kernel(内核),其他参数也是与之相关的。如果kernel='linear',那么模型是线性的,只会用到C参数。如果kernel='rbf',则需要使用C和gamma两个参数,但用不到类似degree的其他参数。在这种情况下,搜索C、gamma和kernel所有可能的组合则没有意义:如果kernel='linear',那么gamma是用不到的,尝试gamma的不同取值将会浪费时间。
为了处理这种“条件”参数,GridSearchCV的param_grid可以是字典组成的列表。列表中的每个字典可扩展为一个独立的网络。包含内核与参数的网格搜索如下所示:
param_grid=[{'kernel':['rbf'],
'C':[0.001,0.01,0.1,1,10,100],
'gamma':[0.001,0.01,0.1,1,10,100]},
{'kernel':['linear'],
'C':[0.001,0.01,0.1,1,10,100]}]
print('grid列表:\n{}'.format(param_grid)) 在第一个网络中,kernel参数始终等于'rbf',而C和gamma都是变化的。在第二个网格中,kernel参数始终等于'linear',只有C是变化的。
在第一个网络中,kernel参数始终等于'rbf',而C和gamma都是变化的。在第二个网格中,kernel参数始终等于'linear',只有C是变化的。
下面应用这个更加复杂的参数:
grid_search=GridSearchCV(SVC(),param_grid,cv=5)
grid_search.fit(X_train,y_train)
print('最佳参数:{}'.format(grid_search.best_params_))
print('最佳精度:{}'.format(grid_search.best_score_))
再次查看cv_results_,正如所料,如果kernel='linear',那么只有C是变化的:
results=pd.DataFrame(grid_search.cv_results_)
print(results.T)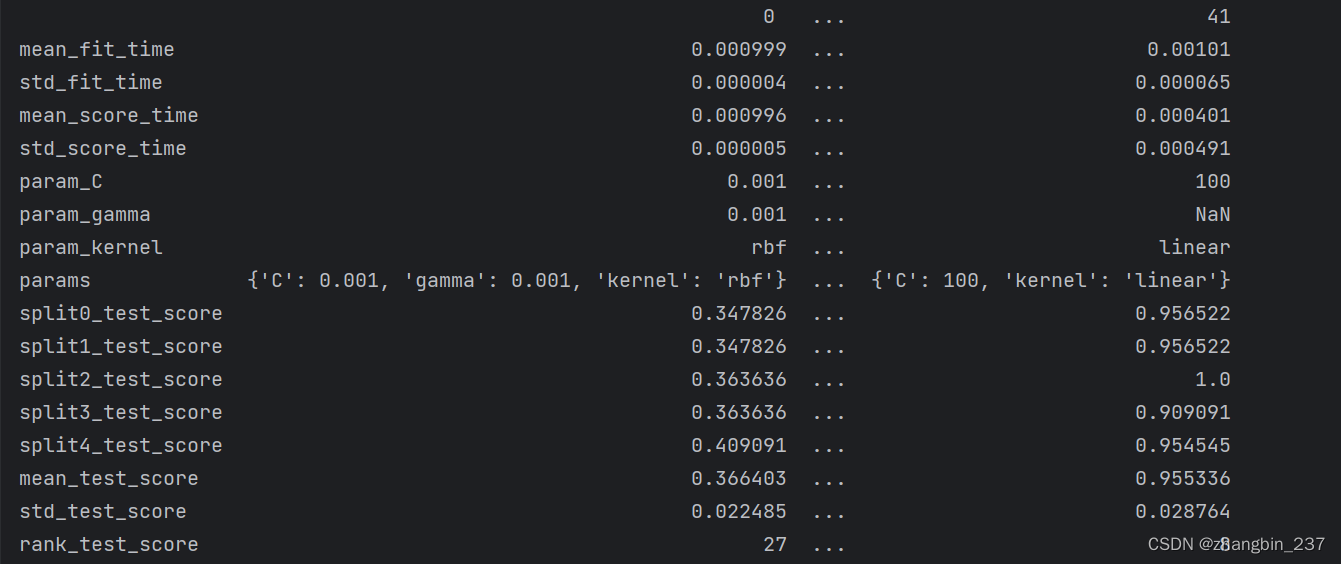
3、使用不同的交叉验证策略进行网格搜索
与cross_val_score类似,GridSearchCV对分类问题默认使用分层k折交叉验证,对回归问题默认使用k折交叉验证。但是,我们可以传入任何交叉验证分离器作为GridSearchCV的cv参数。特别的,如果只想将数据单次划分为训练集和验证集,可以使用ShuffleSplit或StratifiedShuuleSplit,并设置n_iter=1.折对于非常大的数据集或非常慢的模型可能会有帮助。
1、嵌套交叉验证
在前面的例子中,我们将数据单次划分为训练集、验证集、测试集,然后先将数据划分为训练集和测试集,再在训练集上进行交叉验证。但在使用GridSearchCV时,我们仍然将数据单次划分为训练集和测试集,这可能会导致结果不稳定,也让我们过于依赖数据的此次划分。
我们可以深入一点,不是只将原始数据一次划分为训练集和测试集,而是使用交叉验证多次划分,这就是所谓的嵌套交叉验证。在嵌套交叉验证中,有一个外层循环,遍历将数据划分为训练集和测试集的所有划分,对于每种划分都运行一次网格搜索。然后,对每种外层划分,利用最佳参数设置计算得到测试集分数。
这一过程的结果是由分数组成的列表,不是一个模型,也不是一种参数设置。这些分数告诉我们在网格找到的最佳参数下模型的泛化能力好坏。由于嵌套交叉验证不提供可用于新数据的模型,所以在寻找可用于未来数据的预测模型时很少用到它,但是,它对于评估给定模型在特定数据集上的效果很有用。
在scikit-learn中实现嵌套交叉验证很简单。我们调用cross_cal_score,并用GridSearchCV的一个实例作为模型:
scores=cross_val_score(grid_search,iris.data,iris.target,cv=5)
print('最佳参数:{}'.format(scores))
print('最佳精度:{}'.format(scores.mean()))
嵌套交叉验证的结果可以总结为“SVC在iris数据集上的交叉验证平均精度为98%”
这里我们在内层循环和外层循环中都使用了分层5折交叉验证。由于param_grid包含36中参数组合,所以需要构建36*5*5=900个模型,导致嵌套交叉验证过程的代价很高。这里我们在内层循环和外层循环中使用相同的交叉验证分离器,但这不是必需的,你可以在内层循环和外层循环中使用交叉验证策略的任意组合。理解上面单层代码的内容可能有点困难,将其展开为for循环可能有所帮助:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.svm import SVC
from sklearn.model_selection import ParameterGrid,StratifiedKFold
iris=load_iris()
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=0)
param_grid={'C':[0.001,0.01,0.1,1,10,100]
,'gamma':[0.001,0.01,0.1,1,10,100]}
def nested_cv(X,y,inner_cv,outer_cv,Classifier,parameter_grid):
outer_scores=[]
for training_samples,test_samples in outer_cv.split(X,y):
#内层交叉验证,找到最佳参数
best_parms={}
best_score=-np.inf
#遍历参数
for parameters in parameter_grid:
#在内层划分中累加分数
cv_scores=[]
for inner_train,inner_test in inner_cv.split(X[training_samples],y[training_samples]):
clf=Classifier(**parameters)
clf.fit(X[inner_train],y[inner_train])
#在内层测试集上进行评估
score=clf.score(X[inner_test],y[inner_test])
cv_scores.append(score)
#计算内层交叉验证的平均分数
mean_score=np.mean(cv_scores)
if mean_score>best_score:
#如果比前面的模型逗号,则保留参数
best_score=mean_score
best_parms=parameters
clf=Classifier(**best_parms)
clf.fit(X[training_samples],y[training_samples])
outer_scores.append(clf.score(X[test_samples],y[test_samples]))
return np.array(outer_scores)
scores=nested_cv(iris.data,iris.target,StratifiedKFold(5),StratifiedKFold(5),SVC,ParameterGrid(param_grid))
print('精度:{}'.format(scores))
2、交叉验证与网格搜索并行
虽然在许多参数上运行网格搜索和在大型数据集上运行网格搜索的计算量可能很大,但令人尴尬的是,这些计算都是并行的。这也就是说,在一种交叉验证划分下使用特定参数来构建一个模型,与利用其他参数的模型是完全独立的。这使得网格搜索与交叉验证称为多个CPU内核或集群上并行化的理想选择。你可以将n_jobs参数设置为你想使用的CPU内核数量,从而在GridSearchCV和cross_val_score中使用多个内核。你可以设置n_jobs=-1来使用所有可以用的内核。
但是,scikit-learn不允许并行操作的嵌套。因此,如果在模型中使用了n_jobs选项,那么就不能在GridSearchCV使用它来搜索这个模型。如果我们的数据集和模型都非常大,那么使用多个内核可能会占用大量内存,应该在并行构建大型模型时监控内存的使用情况。
还可以在集群内的多台机器上并行运行网格搜索和交叉验证。
对于spark用户,还可以使用最新开发的scikit-learn包,它允许在已经建立好的Spark集群上进行网格搜索。